
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- MMTOD
- Attention Is All You Need
- hugging face tokenizer에서 special case 추가하기
- 다양한 모듈에서 log쓰기
- CNN 논문리뷰
- 길찾기
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문리뷰
- RuntimeError: DataLoader worker (pid(s) ) exited unexpectedly
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 리뷰
- Evaluate Multiwoz
- ImageNet Classification with Deep ConvolutionalNeural Networks 리뷰
- BERT 사용방법
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰
- Attention Is All You Need 리뷰
- BERT란
- BART 논문리뷰
- Multi Task Learning Objectives for Natural Language Processing
- 정책기반 agent
- A Neural Attention Model for Abstractive Sentence Summarization
- Zero-shot Generalization in Dialog State Tracking through GenerativeQuestion Answering
- The Natural Language Decathlon:Multitask Learning as Question Answering
- NLP 논문 리뷰
- 뉴텝스 400
- 바닥부터 배우는 강화 학습
- attention 설명
- UBAR: Towards Fully End-to-End Task-Oriented Dialog System with GPT-2
- Multi Task Learning Objectives for Natural Language Processing 리뷰
- TOD 논문리뷰
- T5 논문 리뷰
- Today
- Total
one by one ◼◻◼◻
[NLP 논문리뷰] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 본문
[NLP 논문리뷰] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
JihyunLee 2022. 4. 13. 20:31논문 : BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
저자 : Mike Lewis*, Yinhan Liu*, Naman Goyal*, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer
1. Introduction
Self-supervised 방법으로 pre trained 된 모델들은 다양한 NLP task에서 성능을 성장시켰지만, BERT 와 같은 모델들은 특정 타입에 end task에만 적용할 수 있는 한계가 있었다. BART는 encoder와 decoder를 결합시킨 모델로 더 다양한 형태의 end task에 적용할 수 있다. Pre training은 corrupted된 sentence를 seq to seq 모델이 다시 origin model로 복구시키는 방법으로 이루어 져 있다. BART는 BERT와 GPT를 결합한 형태이며, 다양한 pre training 방법들이 추가적으로 적용되었다. BART는 generation task에 특히 강하지만, understanding task에도 좋은 성능을 보였다. 텍스트 요약 task에서 새로운 state of the art를 달성하였으며 GLUE, SQuAD 에서 RoBERTa와 비슷한 성능을 보였다. 또한 pre trained된 모델을 이용한 번역 방법을 새롭게 제시하였다.
2.Model

Pre trainingdmfhsms negative log likelihood loss 를 사용하였습니다.
2.1 Architecture
BART는 bidirectional encoder (BERT)와 left-to-right autoregressive decoder (GPT)의 합으로 구성되어있고, GPT와는 다르게 ReLU 대신 GeLUs를 사용하였습니다.
2.2 Pre-training BART
BART는 corrupting documents를 reconstruction하는 것으로 pre-training 되었습니다. 기존의 pre-training 방식이 특정한 하나의 방식의 corrupting 을 사용했다면 BART는 다양한 방법의 corrupting을 사용하였습니다.
- Token Masking : BERT에서 사용 한 것 처럼 랜덤한 토큰을 <MASK> 토큰으로 바꾸는 방식
- Token Deletion : Random 한 토큰을 인풋에서 삭제하는 방법. 이 방법은 Token masking 방식에서, 어디가 사라졌는지도 맞춰야 하는 난이도가 더 높은 방식.
- Text Infilling : Token masking 에서는 하나의 단어만 마스킹 하지만, text infilling 방식은 여러개의 토큰을 한번에 <MASK> 토큰으로 대치
- Sentence Permutation : 문장에 나온 단어의 순서 맞추기. 문장의 단어들이 Shuffle되어서 input이 되면 디코더는 원래 단어의 순서대로 문장을 출력해야 한다.
- Document Rotation : 원래 문장의 단어 순서가 ABCDE 였다면, DEABC 로 순서가 바뀐(회전한?) 문장이 주어진다. 디코더는 다시 원래 형태인 ABCDE로 출력해야 한다.
3. Fine-tunning BART
이 절에서는 BART의 다양한 쓰임에 대해서 알려주고 있다.
3.1 Sequence Classification Tasks
디코더의 마지막 hidden state가 multi class linear classifier input이 되는 방식으로 classification을 진행한다. 이 방법은 BERT가 CLS토큰으로 classification을 하는 것과 비슷하다 (참고로 같인 인코더-디코더 모델인 T5는 class label을 바로 prediction 하는 방식으로 classification을 진행하였다.)
3.2 Token Classification Tasks
start/end token을 맞추는 문제. SQuAD등의 문제에서 사용할 수 있는 방법이며, 디코더의 가장 마지막 hidden state들을 classify하여 사용
3.3 Sequence Generation Tasks
Summarization이나 abstractive에 사용할 수 있다. 인코더는 인풋을 받고, 디코더는 autoregressively하게 output을 생성한다.
3.4 Machin Translation
번역을 할 때에는 인코더를 하나 더 붙여서 사용했다. 하지만 이 방법이 그렇게 좋은가..?에 대한 의문이 있어서 이 부분 설명은 넘어가도록 ..
4. Comparing Pre-training Objectives
실험에 사용한 모델과 데이터셋 설명 그리고 pre-training의 각 방법 비교를 여기서 진행하였다.
pre-training방법 비교 결과는 다음과 같다.
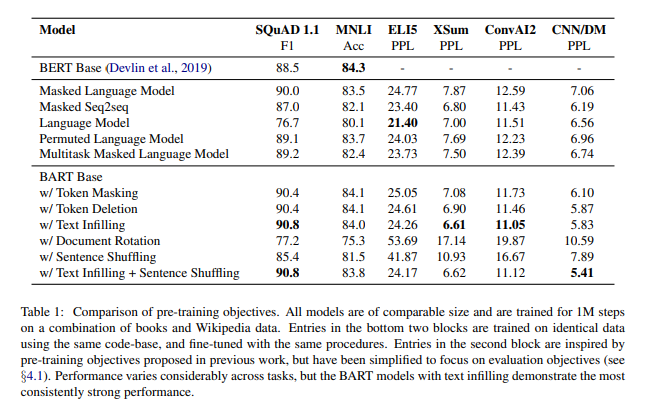
비교 결과 text infilling이 가장 좋은 결과를 보여준 것으로 확인되었다.
5. Large-scale Pre-training Experiments
5.1 Experiment setup
실험을 어떻게 진행하였는지에 대한 설명
분류하는 태스크에서의 실험결과
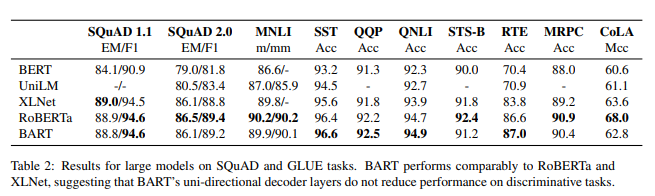
RoBERTa와 대체적으로 비슷한 성능을 보였다.
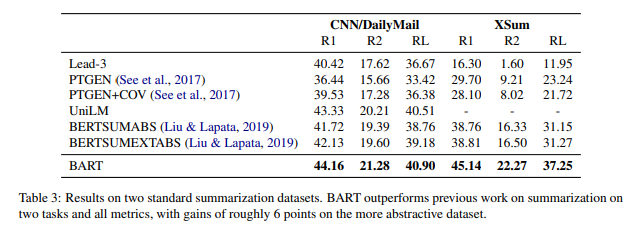
5.3 Generation Tasks
생성하는 태스크에서의 실험결과
Summarization
이 태스크는 원문을 입력받고 이를 요약해야하는 태스크이다.

BART는 특히 요약문을 작성하는데 큰 성능 향상을 보였다.
읽은 후기
이미 T5를 먼저 읽고 BART를 읽었는데, T5논문의 pre view같은 느낌이었다. T5가 더 자세하고 합리적인 실험을 진행하였고, 데이터셋에 대한 설명도 자세하게 해 놓았기 때문이다. 그래서 리뷰를 하긴 했지만.. 별로 추천할만하진 않다...! 다만 abstract 나 summarization에서 좋은 성능을 보였기 때문에 사용하기에는 나쁘지 않을 것 같지만 transformer 베이스의 seq-to-seq모델을 공부하고 싶다면 T5논문을 추천한다



