
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- The Natural Language Decathlon:Multitask Learning as Question Answering
- 길찾기
- attention 설명
- Evaluate Multiwoz
- RuntimeError: DataLoader worker (pid(s) ) exited unexpectedly
- BERT란
- TOD 논문리뷰
- NLP 논문 리뷰
- Multi Task Learning Objectives for Natural Language Processing 리뷰
- Zero-shot Generalization in Dialog State Tracking through GenerativeQuestion Answering
- BART 논문리뷰
- 다양한 모듈에서 log쓰기
- 정책기반 agent
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문리뷰
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Attention Is All You Need
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 리뷰
- A Neural Attention Model for Abstractive Sentence Summarization
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰
- UBAR: Towards Fully End-to-End Task-Oriented Dialog System with GPT-2
- 바닥부터 배우는 강화 학습
- Attention Is All You Need 리뷰
- BERT 사용방법
- Multi Task Learning Objectives for Natural Language Processing
- CNN 논문리뷰
- T5 논문 리뷰
- ImageNet Classification with Deep ConvolutionalNeural Networks 리뷰
- 뉴텝스 400
- hugging face tokenizer에서 special case 추가하기
- MMTOD
- Today
- Total
one by one ◼◻◼◻
[NLP 논문리뷰] Attention Is All You Need(1) 본문
제목 : Attention Is All you Need

저자 : Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
링크 : https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
이번 주에는 BERT, GPT, T5등 Attention 기반의 구조의 기초를 깔아준 논문인 Attention Is All You Need 논문을 읽어보았습니다. 개인적으로는 NLP가 지금처럼 발전하게 된 것에 아주 큰 영향을 끼친 논문이라고 생각합니다. 그럼 리뷰 시작하겠습니다. 🎈
1. Introduction
기존의 NLP task에는 RNN 계열의 구조와 CNN구조가 많이 사용되었습니다. 그러나 CNN은 구조적으로 전체 문장을 한번에 볼 수 없고(아래 그림 참고), RNN은 순차적으로 문장을 읽어서 전체 문장을 볼 수는 있지만, 문장이 길어지면 초반의 내용이 마지막 레이어(마지막 단어) 까지 전달이 되지 않는다는 문제점이 있었습니다.


Attention Mechanism은 RNN이 가지고 있는 한계를 극복하기 위해 나온 방법으로, Attention Layer 를 두어, 마지막 단어의 hidden vector까지 전체 문장을 반영할 수 있도록 만든 방법입니다.

논문은 CNN과 RNN을 전혀 사용하지 않고 Attention만 사용해서 만든 새로운 네트워크 Transformer를 제안합니다. 이 구조는 분산학습이 가능하며, 번역 부분에서 새로운 State of the art를 달성하였습니다.
2. Background
위와 비슷하게, RNN과 CNN구조에 대해 설명하고 있습니다. 스킵하겠습니다!
3. Model Architecture
대부분의 시퀀스 데이터를 다루는 모델을 인코더와 디코더 형태를 가지고 있습니다. Transformer도 마찬가지로 인코더아 디코더를 가지고 있습니다. 인코더는 문장 x=(x1,2,x3,x4...)을 받아서 z = (z1,z2,z3..)로 바꿔주고, 디코더는 z를 받아 Output sequence인 y=(y1,y2,y3..)로 바꿔줍니다.
3.1 Encoder and Decoder Stacks
Encoder : 인코더는 N = 6개의 동일한 레이어가 중첩된 형태로 구성되어 있습니다. 각각의 레이어는 Multi-head attention 과 Feed Forward라는 두개의 서브 레이어로 나눠지게 됩니다. 그리고 각 서브 레이어에 residual connection(입력값이랑 출력값을 합쳐주는것)을 두고, Add & Norm 에서 입력값과 출력값이 합쳐진 뒤, layer normalize가 일어나도록 하였습니다.
Decorder : 디코더는 또한 N=6으로 동일하게 중첩된 레이어를 가지고 있으며 인코더에는 두개의 sub layer가 있는 것과 달리, 세개의 sub layer가 존재합니다. 세번째 레이어는 encoder stack과 함게 multi head attention을 진행하게 됩니다(Attention에 대해서는 곧 설명..!). 인코더와 동일하게 여기도 각 서브 레이어마다 residual connection 과 layer noramlize를 두었습니다. 디코더의 multi head attention은 생성된 문장 이후의 단어는 attention 을 하지 못한다는 점에서 인코더의 multi head attention과 차이가 있습니다(아직 생성되지 않은 단어는 미지의 단어이기 때문입니다! 이에 대해 뒤어 더 자세히 설명하겠습니다.).
3.2 Attention
그렇다면 대체 Attention은 무엇일까요? Attention은 말 그대로, 한 문장내에서 특정 단어를 이해하려고 할때(또는 생성하려 할 때) 어떤 단어들을 중점적으로 봐야 단어를 더 잘 이해할 수 있을지(또는 생성) 에 관한 것입니다.
appendix 에 보면 attention을 visualize한 것이 있습니다. making 이라는 단어를 이해할 때 어떤 단어들에 attention을 두었는지 이해할 수 있는 그림입니다.

3.2.1 Scaled Dot-Product Attention
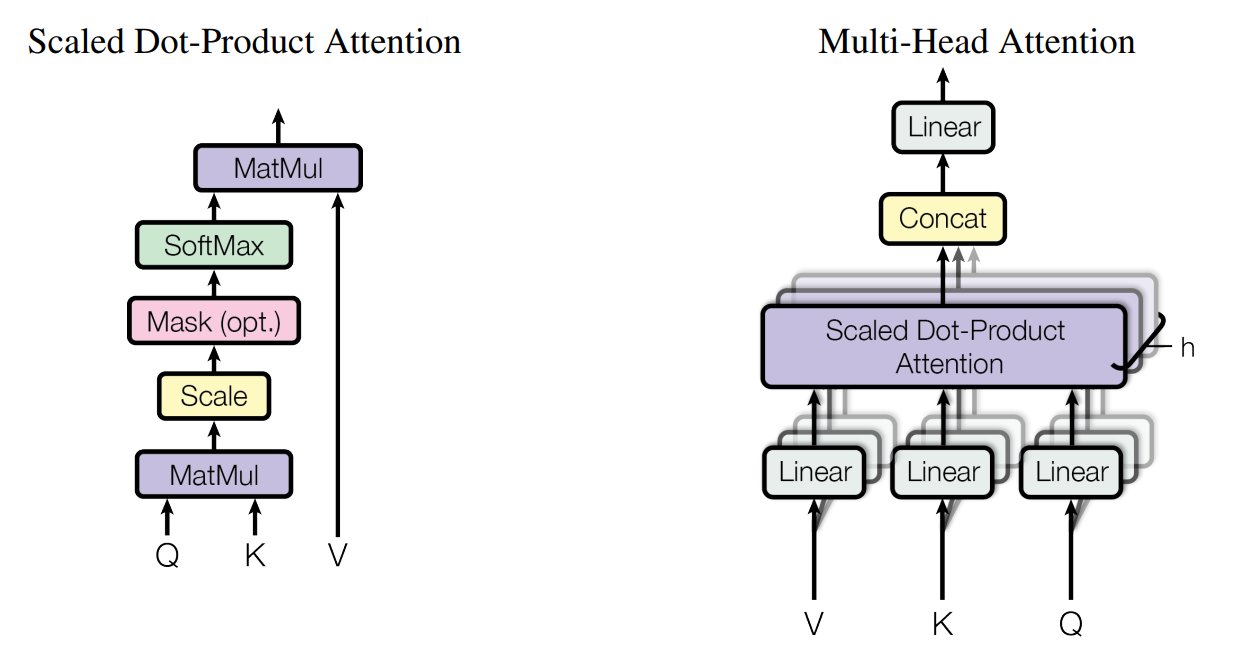
Attention은 Q(query), K(key), V(value)로 이루어집니다. 각 단어 토큰들은 Query, Key, Value값들을 각각 가지고 있고, Query 와 Key를 곱하면, 단어의 중요도가 나오고 이를 value에 곱해 중요도를 반영한 value를 얻는 것이죠!
좀더 쉽게 예시를 들어보자면 I love you라는 단어가 있을 때, I_Q, love_Q, you_Q를 각 단어의 쿼리벡터, I_Key, love_Key, you_Key를 키 벡터라고 한다면, love라는 단어를 이해할 때, you라는 단어가 얼마나 중요한지 알아 보려고 한다면, love_query를 you_key 와 곱하면 되는 것입니다.
저는 이 개념을 처음 들었을 때 왜 두 벡터를 곱한 값이 중요도를 나타내는지 이해가 안됐는데, query 벡터, key 벡터 모두 '학습가능한' 벡터 이기 때문에, 처음엔 중요도를 나타내지 않더라도, 학습을 계속하면서 중요도를 나타 낼 수 있게 된다고 이해했습니다.
다시, I love you 라는 문장에서 love를 이해하는 과정으로 돌아간다면, love를 이해하기 위해서 I_key * love_Q, love_key * love_Q, you_key*love_Q 연산을 해 준뒤 이 세개의 값을 soft max를 취해주면(0,20 ,0.5, 0.3) 와 같이 확률값이 나오게 됩니다. 이 결과는 love를 이해하기 위해서는 love>you>I 순으로 중요한 의미가 있다는 결과가 됩니다.
이 결과를 다시 각각의 value와 곱해주면 (I_value * 0.2 + love_value * 0.5 + you_value * 0.3) love에 대한 attention 값이 되는 것이죠!
Attention 의 수식은 아래와 같습니다. 여기서 normalize term인 1/root(dk) 가 있는데 이는 attention값이 너무 극단적으로 가는 것을 (예를들어 0.9999, 0.00001) 방지해 준다고 합니다.
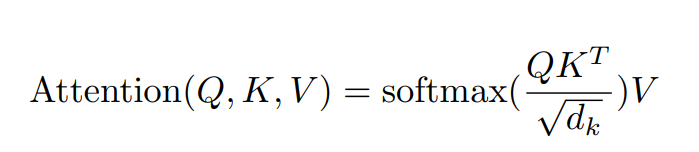
3.2.2 Multi-Head Attention
논문에서는 하나의 single attention을 두지 않고 총 8개의 attention vector를 두어서 multi head attention을 사용하였고, 효과가 더 좋았다고 합니다. 여기서 multi head를 둔 이유는 사람마다 단어를 이해하는게 다르듯, 모델도 그러한 효과를 노린것이라고 하네요!(이건 논문에서 한 말은 아니고 유튜브에서 공부한 내용입니다)
multi head attention을 해도, 벡터 연산이기 때문에 적은 연산 횟수로도 구현이 가능하다는 장점이 있습니다.

이 어텐션을 어떻게 모델에 적용했는지는 다음 post에 기술하도록 하겠습니다.😉🧡
2편 :
2021.12.26 - [논문리뷰] - [NLP 논문리뷰] Attention Is All You Need(2)
Reference
1. Kim, Yoon. "Convolutional neural networks for sentence classification. CoRR abs/1408.5882 (2014)." arXiv preprint arXiv:1408.5882 (2014).
2. https://colah.github.io/posts/2015-08-Understanding-LSTMs/
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 <!-- by colah --> Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
1) 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 ...
wikidocs.net



