
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 정책기반 agent
- Multi Task Learning Objectives for Natural Language Processing 리뷰
- Attention Is All You Need 리뷰
- MMTOD
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문리뷰
- The Natural Language Decathlon:Multitask Learning as Question Answering
- attention 설명
- Attention Is All You Need
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 리뷰
- Multi Task Learning Objectives for Natural Language Processing
- 다양한 모듈에서 log쓰기
- hugging face tokenizer에서 special case 추가하기
- A Neural Attention Model for Abstractive Sentence Summarization
- 뉴텝스 400
- 바닥부터 배우는 강화 학습
- BART 논문리뷰
- UBAR: Towards Fully End-to-End Task-Oriented Dialog System with GPT-2
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- RuntimeError: DataLoader worker (pid(s) ) exited unexpectedly
- Evaluate Multiwoz
- BERT란
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 리뷰
- CNN 논문리뷰
- Zero-shot Generalization in Dialog State Tracking through GenerativeQuestion Answering
- TOD 논문리뷰
- T5 논문 리뷰
- ImageNet Classification with Deep ConvolutionalNeural Networks 리뷰
- 길찾기
- BERT 사용방법
- NLP 논문 리뷰
- Today
- Total
one by one ◼◻◼◻
[NLP] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 리뷰(T5)-2 본문
[NLP] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 리뷰(T5)-2
JihyunLee 2021. 11. 27. 00:15저자: Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu
링크 : https://arxiv.org/abs/1910.10683
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a div
arxiv.org
어쩌다 보니 3번에 나누어서 읽게 된 T5 논문! 앞부분에 이어서 계속 리뷰를 해 보겠습니다!
3.3 Unsupervised Objective
3 장은 계속해서 다양한 실험을 진행합니다. 3.3 Unsupervised Objectives 는 T5의 pretrainning시, 데이터의 형태를 어떻게 하는것이 좋을지에 대한 실험을 진행합니다.

지금까지 나왔던 pretrainning 데이터 형태를 모두 실험해 보았는데, Prefix language modeling은 앞에 input으로 문장의 앞부분을 넣으면 Target으로 문장의 뒷부분을 예측하는 방식, Bert-style은 토큰의 15%를 masking하고 15%중 90% 를 랜덤한 token으로 변경 한 뒤 original text를 예측해야하는 방식, Deshuffling은 랜덤하게 섞인 문장을 보고 원 문장을 예측해야하는 방식, Mass style은 Bert 방식에서 90%의 랜덤 토큰 변경 방법을 제외한 것 입니다. 아래 세개(5,6,7번)는 이 논문에서 제안한 형태로 5번은 가려진 masking부분만을 예측하는 task, 6번은 masking을 알려주지않아도 빠진 문장을 채워넣어야 하는 task, random span은 1개의 span이 아니라 더 긴 span을 예측하도록 한 task입니다.
기존에 있던 방식인 1,2,3 방식을 실험한 것의 성능은 Bert-style이 가장 좋았습니다.

Bert style과 4,5,6 방식을 비교하였을 때는 5번 방식이 가장 좋은 성능을 보였습니다. 또한 Target sentence의 길이가 짧기 때문에 학습시간이 더 짧았습니다.

corruption rate( masking rate)를 실험한 결과는 다음과 기존 버트와 같은 15%가 가장 좋았습니다.
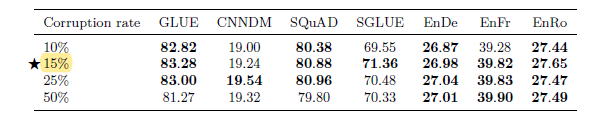
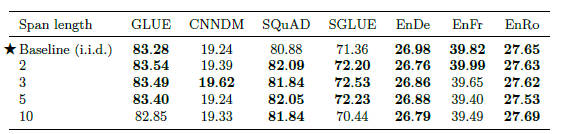
또한 masking의 길이를 다양하게 했을때는(span을 1개만 masking, 여러개 masking) 기존의 하나의 span만 masking하는 방식이 가장 좋았으나, 다른 masking방법들도 크게 나쁘지 않았기 때문에, 이는 fine tunning task에 따라 조절 가능합니다.
위 설명한 실험 과정을 요약한 그림은 아래와 같습니다.

3.4 Pre-training Dat set
다음으로는 pre-training시 사용한 dataset에 관한 실험을 진행하였습니다.
실험에 사용한 데이터 셋은 1. 기존의 C4 dataset, 2. 정제하지 않은 C4, 3. 뉴스데이터 4. Reddit과 같은 실제 인터넷 데이터 5. 위키피디아 6. 버트에서 사용한 위키피디아 + Toronto books corpus 입니다.

실험결과 C4가 가장 좋았고, 정제되지 않은 데이터는 성능이 떨어지는것을 확인할 수 있었습니다.
또한 데이터의 양에 대한 실험도 진행하였습니다.
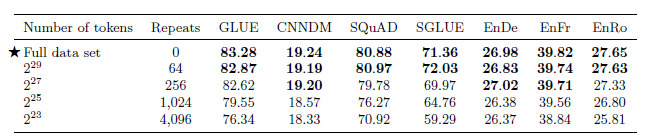
Full data set 의 span은 2^35 개 이고, 이를 점진적으로 줄여서 실험하였습니다. Span의 수를 줄인 대신, 줄어든 만큼의 반복횟수를 거쳤습니다. 결과를 보았을 때 pre trainning dataset을 여러번 반복하는 것 보다는 하나의 큰 데이터 셋을 가지고 있는것이 더 좋은 결과가 나오는 것을 알 수 있습니다.
3.5 Training Strategy
다음은 Trainning 방법에 대한 실험을 진행하였습니다. 여기서 말하는 Trainning은 fine tunning시를 의미합니다.
논문에서는 Fine tunning 방식을 adapter layers(pre trainning이 된 부분을 그대로 두고 그 위에 별도의 학습 가능한 layer를 두어 그 부분만 학습시키는 방법)과, gradual unfreezing방식(top layer부터 bottom까지 천천히 학습되는 방법, 가장 아래 레이어가 가장 늦게 unfreezing된다.) 두개를 소개하고 이를 비교하였습니다.

비교한 방식의 결과로는 모든 parameter를 freezing하지 않고 학습시켰을때 결과가 가장 좋았습니다.



